

1. SP-GiST 인덱스란?
Space-Partitioned Generalized Search Tree의 약자이다. GiST인덱스와 같이 지리, 좌표, ip주소 데이터 등 복잡한 유형의 데이터를 처리하는 인덱스 유형이다. GiST가 B-tree 인덱스를 통해 보관 데이터를 세분화할 때, 위계적 순서를 따라야 하기에, 이를 보완하기 위해 만들어진 유형으로, GiST로 분리된 공간을 다시 한번 공간 단위로 나누어 관리하는 개념이다. SP-GiST는 겹치지 않는 영역으로 재귀적 분할을 할 수 있는 구조에 적합하다. 기본적으로 SP-GiST는 다양한 데이터 유형, 복잡한 쿼리를 지원하도록 설계되었다.
1-1. SP-GiST 인덱스 생성
CREATE INDEX idx_spgist_example ON example_table USING spgist (column1);1-2. 장점
다양한 종류의 데이터 타입에 사용 가능 : 기하학, IP, 다른 복잡한 데이터 타입
복잡한 쿼리에 사용 가능 : 복잡한 데이터구조, 쿼리에 사용 적합하도록 설계
빠른 검색 효율
1-3. 단점
복잡한 구현 방법 : btree/hash 에 비해 구현이 복잡하다.
느린 업데이트 : SP-GiST index는 업데이트가 느리다, 복잡한 알고리즘인 만큼 특정 데이터 변경시 인덱스의 업데이트가 느리다.
한정된 쿼리 유형 : 복잡한 유형의 쿼리에 특화 되어있다보니 =, <등 간단한 타입의 비교에는 고려되지 않을 수 있다.
1-4. 그렇다면 SP-GiST는 GiST인덱스와 어떻게 다를까?
▪ 1-4-1. Operator
▪ GiST에 비해 SP-GiST를 지원하는 operator가 적다. (SP-GiST 지원 Operator는 아래에서 확인가능)
(GiST는 (k) NN searches를 포함한 모든 operator 지원을 받는다.)
▪ 1-4-2. 인덱스 생성 시간
▪ GiST 인덱스의 생성시간은 데이터 증가에 따라 비선형적이지만 안정적으로 증가한다.
▪ SP-GiST 인덱스는 적은 데이터일 경우 빠르지만, 몇 억 건이 넘어갈 경우 GiST에 비해 현저히 떨어지는 속도를 보인다.
▪ 1-4-3. 데이터 밀집도에 따른 효율성
▪ GIST는 기하학적 구조의 공간 분포와 토폴로지에 크게 민감하지 않다.
▪ SP_GIST는 공간 분할(Spatial Partitioning)로 인해 중첩되지 않는 지오메트리에 가장 효과적이며 공간적으로 균일한 분포에 대한 검색에 효율적이다.
데이터 사이즈, 구조, 사용하는 쿼리 등에 따라 인덱스의 효율성이 달라질 수 있어, 실제 데이터로 GiST, SP-GiST의 성능테스트가 꼭 필요하다.
2. 지도 / 좌표 형태의 데이터 인덱싱
다음과 같이 위도/경도 데이터로 조회를 시도할 시 효율적이다
SELECT city_name
FROM locations
WHERE ST_DWithin(ST_MakePoint(:longitude, :latitude), ST_MakePoint(longitude, latitude), :distance);

지도의4분 할로 지속적으로 나눈다. 각각의 사각형이 index page 역할을 한다
나눠진 부분을 좀 더 상세히 보면
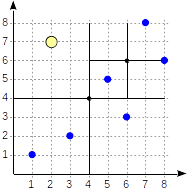
다음 좌표에서 (2,7) 위에 존재하는 좌표들을 찾고 싶다면
select * from points where p >^ point '(2,7)'(4,4)를 (2,7)과 비교하여 더 큰 좌표가 존재할 수 있는 영역을 확인한다.
1 사분면의 중심좌표인 (6,6)으로 다시 비교하여 더 큰 좌표가 존재할 수 있는 영역을 확인한 후 다음과 같은 인덱스 구조를 생성한다.

3. Built-in Operator Class
| Name | Indexable Operators | Ordering Operators |
| box_ops | << (box,box) | <-> (box,point) |
| &< (box,box) | ||
| &> (box,box) | ||
| >> (box,box) | ||
| <@ (box,box) | ||
| @> (box,box) | ||
| ~= (box,box) | ||
| && (box,box) | ||
| <<| (box,box) | ||
| &<| (box,box) | ||
| |&> (box,box) | ||
| |>> (box,box) | ||
| inet_ops |
<< (inet,inet) | |
| <<= (inet,inet) | ||
| >> (inet,inet) | ||
| >>= (inet,inet) | ||
| = (inet,inet) | ||
| <> (inet,inet) | ||
| < (inet,inet) | ||
| <= (inet,inet) | ||
| > (inet,inet) | ||
| >= (inet,inet) | ||
| && (inet,inet) | ||
| kd_point_ops |
|>> (point,point) | <-> (point,point) |
| << (point,point) | ||
| >> (point,point) | ||
| <<| (point,point) | ||
| ~= (point,point) | ||
| <@ (point,box) | ||
| poly_ops |
<< (polygon,polygon) | <-> (polygon,point) |
| &< (polygon,polygon) | ||
| &> (polygon,polygon) | ||
| >> (polygon,polygon) | ||
| <@ (polygon,polygon) | ||
| @> (polygon,polygon) | ||
| ~= (polygon,polygon) | ||
| && (polygon,polygon) | ||
| <<| (polygon,polygon) | ||
| &<| (polygon,polygon) | ||
| |>> (polygon,polygon) | ||
| |&> (polygon,polygon) | ||
| quad_point_ops |
|>> (point,point) | <-> (point,point) |
| << (point,point) | ||
| >> (point,point) | ||
| <<| (point,point) | ||
| ~= (point,point) | ||
| <@ (point,box) | ||
| range_ops |
= (anyrange,anyrange) | |
| && (anyrange,anyrange) | ||
| @> (anyrange,anyelement) | ||
| @> (anyrange,anyrange) | ||
| <@ (anyrange,anyrange) | ||
| << (anyrange,anyrange) | ||
| >> (anyrange,anyrange) | ||
| &< (anyrange,anyrange) | ||
| &> (anyrange,anyrange) | ||
| -|- (anyrange,anyrange) | ||
| text_ops |
= (text,text) | |
| < (text,text) | ||
| <= (text,text) | ||
| > (text,text) | ||
| >= (text,text) | ||
| ~<~ (text,text) | ||
| ~<=~ (text,text) | ||
| ~>=~ (text,text) | ||
| ~>~ (text,text) | ||
| ^@ (text,text) |
참고
https://www.postgresql.org/docs/current/spgist-builtin-opclasses.html
https://gis.stackexchange.com/questions/374091/when-to-use-gist-and-when-to-use-sp-gist-index
'Postgresql' 카테고리의 다른 글
| [PostgreSQL] BRIN 인덱스의 원리 및 특징 (0) | 2023.09.18 |
|---|---|
| [PostgreSQL] GIN인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] GiST인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] Hash 인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] B-tree 인덱스의 원리 및 특징 (27) | 2023.09.12 |