

1. GiST 인덱스란?
Generalized Search Tree의 약자이며 B-tree와 같은 balanced search tree의 형태이다. B-tree인덱스는 정렬된 채로 비교&일치의 연산에 최적화된 채로 연결되어있다. 하지만 현대의 다양한 데이터 종류 (기하학적, 텍스트문서, 이미지 등)를 연산하는 데는 적합하지 않다.
GiST 인덱스는 이러한 데이터 타입의 인덱싱을 위해 설계되었다. GiST 인덱스는 각 유형의 데이터를 Balanced tree 형태로 구성하게하고, tree에 접근하는 연산자를 정의해 준다. 각각 leaf node는 table row(TID)와 boolean 형태의 predicate를 가지고 있고 인덱스 데이터(key)는 이 predicate와 부합한다. 그 후는 일반적인 tree search처럼, 루트노드에서 시작하여, 어떤 child node로 진입할지를 결정한다. 그러다가 leaf node를 발견하면, 그 결과들을 반환한다.
SELECT city_name
FROM locations
WHERE ST_DWithin(ST_MakePoint(:longitude, :latitude), ST_MakePoint(longitude, latitude), :distance);그렇기에 다음과 같은 위/경도를 통한 위치정보의 검색에 효율적인 인덱스이다.
▪ 1-1. 지도(좌표)형태의 데이터 인덱싱
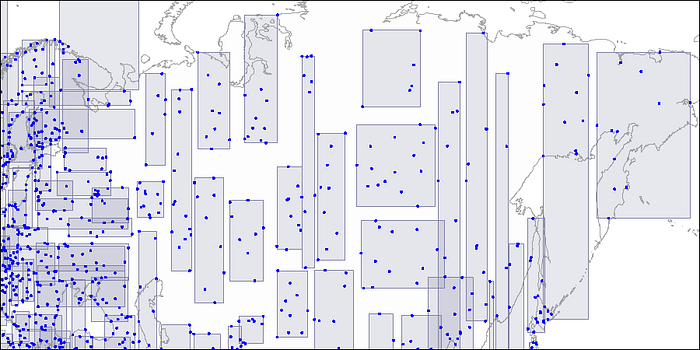
지도, 좌표 형태의 데이터에 유용하며 지도의 특정 분포지점을 사각형으로 계속해서 분할한다. 각각의 사각형이 index page 역할을 한다.
ROOT page 는 몇몇 최대로 큰 사각형을 보유하고 있으며, child nodes는 큰 사각형들에 포함된 작은 사각형들을 포함하고 있어 모든 point들을 커버할 수 있도록 구성된다.
좀 더 자세히 들여다보자
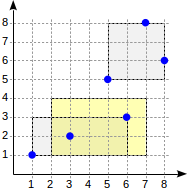
다음 좌표를 보면 (2,1)-(7,4) 사각형은 (1-1)-(6,3)과 겹치지만 (5-5), (8-8) 사각형과는 겹치지 않는다, 그렇기 때문에

다음과 같은 방법으로 하위 leaf를 결정하게된다.
참고 : https://postgrespro.com/blog/pgsql/4175817
'Postgresql' 카테고리의 다른 글
| [PostgreSQL] GIN인덱스의 원리 및 특징 (0) | 2023.09.13 |
|---|---|
| [PostgreSQL] SP-GiST인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] Hash 인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] B-tree 인덱스의 원리 및 특징 (27) | 2023.09.12 |
| [PostgreSQL] 인덱스(INDEX)개념 및 생성, 삭제, 분석, 설계 방법 (27) | 2023.09.12 |