

PostgreSQL에는 6가지의 인덱스 종류가 있다. 각각의 인덱스는 다양한 데이터 탐색을 위해 다른 알고리즘을 사용한다.
그중 가장 일반적으로 사용되고, 가장 먼저 도입된 알고리즘인 B-tree 인덱스에 대해 알아보자.
1. B-tree 인덱스란?
▪ 트리의 노드를 밸런스 있게 재정렬한 트리형태의 자료구조
▪ B-tree는 Binary 가 아닌 Balanced의 약자
▪ 컬럼의 기존 데이터를 변형하지 않음
▪ 인덱스 구조체 내에서는 항상 정렬된 상태를 유지
2. B-tree 인덱스의 원리
▪ 2-1. B-tree 인덱스의 자료구조 형태
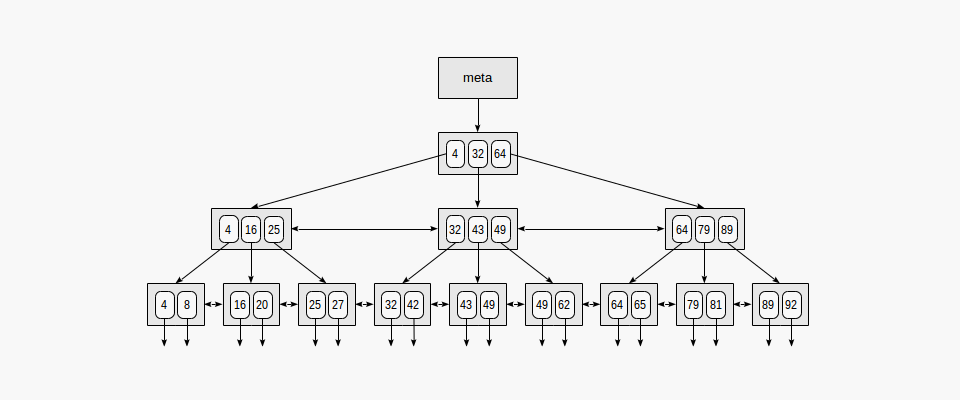
최상위 Root를 Meta page, 최하위 노드를 Leaf page라고 한다.) Root page에서 leaf page들 간의 내부 page 수가 항상 같기에, 어떤 value를 검색하여도 동일한 시간이 걸린다. 데이터는 non-decreasing order로 정렬되어 있고, 동일 레벨의 page들끼리는 양방향으로 연결되어 있기에 (ex. 그림의 25 <->32) 순차적 데이터를 root를 확인할 필요 없이 한 번에 찾을 수 있다.
▪ 2-2. 정확히 일치하는 데이터를 찾기 위해 데이터를 탐색하는 순서 ("indexed-field = expression")
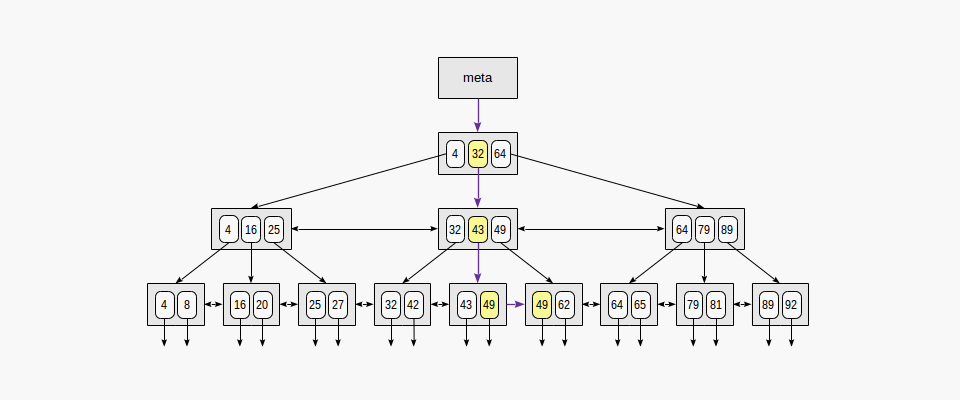
인덱스 컬럼에 동일 데이터가 너무 많이 분포되어있어 한 page에 넘치게 데이터가 들어있을 수 있기에, 내부 페이지에서 정확히 일치하는 page를 찾게 되면 왼쪽으로 한 page를 이동하여 left to right 방향으로 인덱스를 조회한다.
▪ 2-3. 불일치에 해당하는 데이터를 찾기 위해 데이터를 탐색하는 순서 ("indexed-field ≤ expression" (or "indexed-field ≥ expression")),
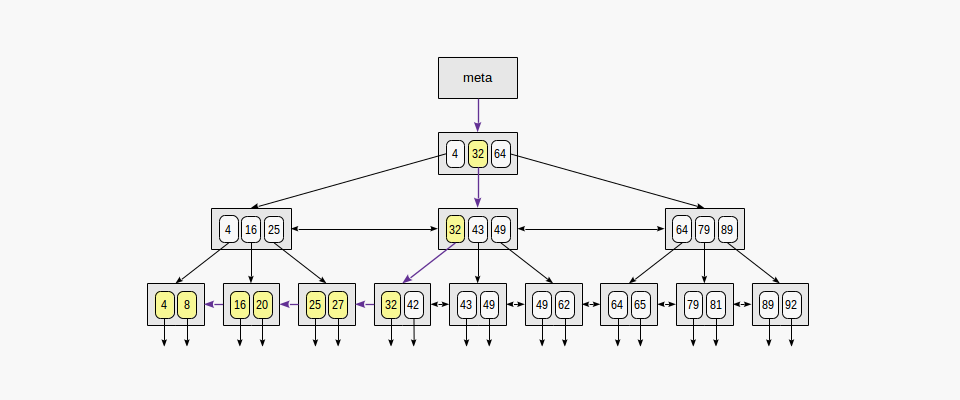
다음의 경우, 먼저 일치하는 leaf page 를 찾은 후 leaf page 간의 이동으로 조회한다.
▪ 2-4. 범위로 조회할 경우 데이터를 탐색하는 순서 ("indexed-field ≤ expression" and "indexed-field ≥ expression"),
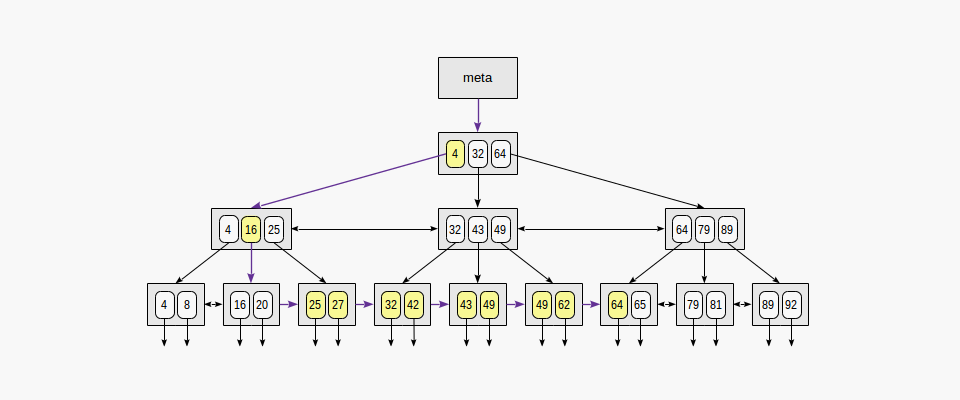
A< indexed-field < B 일경우 A에 해당하는 leaf page를 찾은 후 B의 조건에 맞는 범주 내의 데이터까지 leaf page 간의 이동으로 조회한다. 혹은 반대 방향으로, B부터 조회 후 A 조건에 맞는 데이터 범주까지 leaf page 간 이동하여 조회한다.
3. B-tree 인덱스의 특징
인덱스 자체의 특징 및 설계방법은 이전 포스트 (https://junhkang.tistory.com/5) 에서 다루고 있으니 참고, B-tree 인덱스만의 특징은 다음과 같다.
▪ 데이터가 동일한지, 특정 범주에 있는 데이터인지 여부로 조회할 때 사용
▪ Postgresql 옵티마이저는 "< <= = >= >"와 같은 수식을 사용할때 B-tree 인덱스를 고려 (수식의 조합인 IN&& Between도 고려)
▪ IS NULL, IS NOT NULL 조건도 인덱스 사용 가능
▪ 패턴매칭 (like)도 문자열의 시작에 매칭을 사용하지 않으면 적용 가능 ( ‘test%’, ‘test^’)
▪ Ilike, ~* 에는 패턴이 알파벳 외의 문자(대/소문자 영향을 안 받는 문자로 시작하는 경우)로 시작할 때만 사용 가능
'Postgresql' 카테고리의 다른 글
| [PostgreSQL] GiST인덱스의 원리 및 특징 (0) | 2023.09.13 |
|---|---|
| [PostgreSQL] Hash 인덱스의 원리 및 특징 (0) | 2023.09.13 |
| [PostgreSQL] 인덱스(INDEX)개념 및 생성, 삭제, 분석, 설계 방법 (27) | 2023.09.12 |
| Postgresql Lock이란? (조회 및 kill, Dead lock) (29) | 2023.09.11 |
| [PostgreSQL] Trigger, Procedure, Function (history 관리하기) (21) | 2023.09.08 |